
Unlocking the Potential of Big Data in the AI Era: Overcoming the Challenges Rise of AI
November 27, 2023
In modern technology-driven world, artificial intelligence (AI) has captured the spotlight, revolutionizing industries and transforming our daily lives. This surge in AI development is inextricably linked to the rise of the Internet of Things (IoT), a network of interconnected devices generating massive amounts of data. This data is characterized by the three Vs - volume, velocity, and variety.
Volume stands for sheer amount of data that is being generated and stored.
Velocity refers to the speed at which the data is generated.
Variety stands for the diversity of the generated data.
The advent of deep neural networks in 1985/1986 ushered in an era of data-driven problem-solving, enabling the tackling of complex challenges that were previously insurmountable.
A turning point came in 1986 when Geoffrey Hinton, David Rumelhart, and Randy Williams published a "Learning representations by back-propagating errors." This paper introduced the concept of backpropagation, an algorithm for efficiently training neural networks, which significantly improved their performance.
The main difference between traditional and AI methods is that in traditional methods we know the input, define the strict chain of rules which outcome is something that we definitely know should be.
In AI, we define the input data, output data, and the number of parameters and their interconnections within the model. Through the learning/training process, this 'magic function' learns to map the input data to the desired output.
Since deep neural networks are most well performing in the context of reliability, accuracy, we still need to put an immersive effort into input data processing and defining the output/labels.
These endeavors are notably resource-intensive, particularly in domains that require expert knowledge such as healthcare, law, deep-tech, and advanced scientific disciplines. Furthermore, a key challenge lies in the error-prone nature of this process. Data, especially in fields like medical imaging is multidimensional from 2D to 4D and processing, exploring the data is time intensive.
Building AI with less Resources
There are two main methods that allow to build annotated dataset in an effective way:
- active learning
- core-set selection
Active learning, which has gained popularity among R&D teams, is an iterative machine learning process that helps with selecting data to label for training.
Overall active learning has the following steps:
- label small amount of the dataset
- train the model
- query the next portion of the images and train again
There are different methods to define the query function, which will be discussed in later posts. Just for evidence we will describe uncertainty sampling based example:
Initial Training: Train the DNN(deep neural network) using an initial small set of labeled images for different classes (e.g., covid, normal, viral pneumonia).
Predict on Unlabeled Data: Evaluate the training DNN on the remaining unlabeled images.
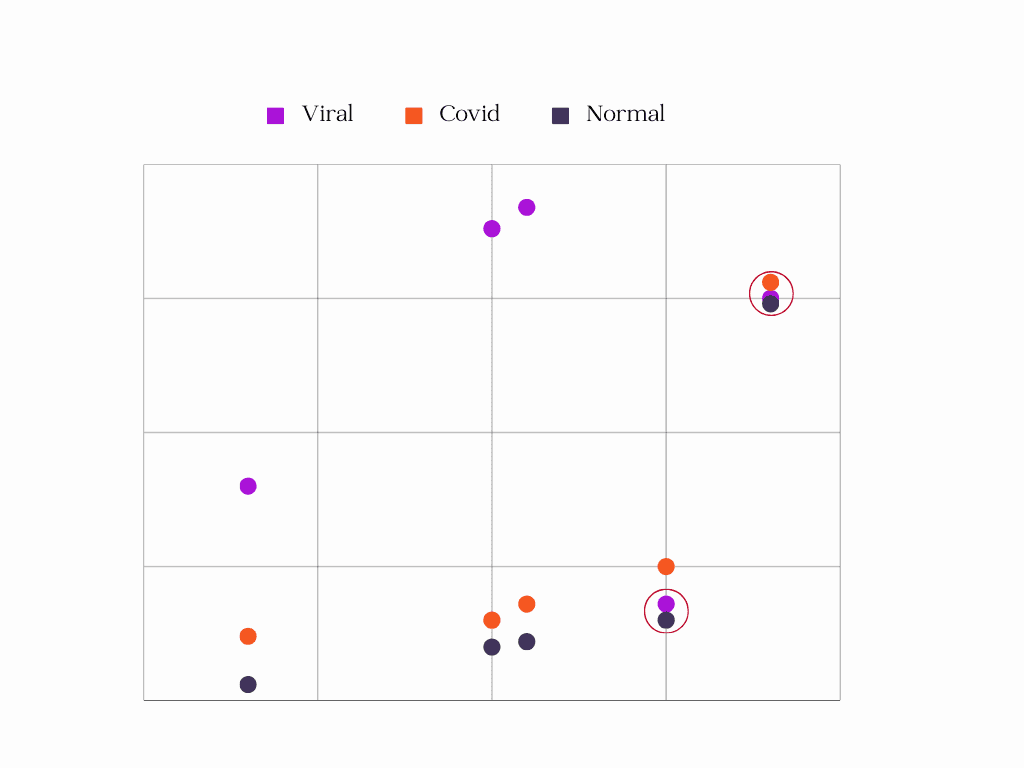
Uncertainty scores
Calculation: Compute uncertainty scores based on a chosen uncertainty measure. For instance, we can use a method like entropy to quantify uncertainty.
Entropy: Calculate the entropy of predicted probabilities. Higher entropy indicates higher uncertainty. For example, an image (that) where the model predicts (equally probable) as a viral pneumonia, normal, and covid with the close probabilities has high entropy.
Select Uncertain Images: Select the N images with the greatest degree of uncertainty. These images are those for which the model's predictions are least certain or trustworthy.
Expert annotation: Share the selected uncertain images with human annotators for labeling. Experts provide the correct labels for these images.
Retrain the model: Add the newly labeled images into the training set and retrain the DNN.
Iterative Process: Repeat steps 2-6 iteratively. The model progressively improves as it learns from the labeled uncertain samples, enhancing its ability to generalize and make more accurate predictions.
Active learning identifies the most impactful samples to label, significantly reducing labeling efforts but not always budgets, since for several deep neural networks might require involvement of expensive GPU-server utilization.
Active Learning's Double-Edged Sword: Enhancing Efficiency at the Expense of Robustness
However, it is difficult with active learning methods to make machine learning models more robust to noise and outlier.
There cons lay in the following areas:
Selection bias: Active learning algorithms may introduce selection bias, where the selected data points are not representative of the entire dataset. This bias can lead to models that are not robust to noise and outliers.
Oracle dependency: Active learning often relies on an oracle or a human expert to label the data. This dependency can introduce noise and outliers into the labeled data, which can impact the model's robustness.
Computational complexity: Some active learning algorithms can be computationally expensive, making them impractical for large datasets or real-time applications.
Core-set Selection Method
The next method that optimizes the workflow, reduces labeling efforts and expenses, is the core-set selection. Core-set selection technique is a dataset optimization method in machine learning that aims to select a representative subset of raw data from a large unstructured dataset. However, the core-set selection methods in general might require understanding the data.
Core-set selection methods we can categorize in two main ways:
- Clustering based Kmeans, hierarchical clustering, etc.
- Sampling based Random sampling: This method selects a subset of data points uniformly at random, resulting in an unbiased representation of the dataset.Stratified sampling: This method selects data points proportionally to their representation in the dataset, ensuring that each stratum or group is adequately represented in the subset.Importance sampling: This method selects data points based on their importance or influence on the target learning task, prioritizing points that are more informative for training or prediction.
Paying Tribute to Core-set Selection
Core-set selection is impactful to apply in
- Continuous learning: When machine learning models are continuously updated with new data, core set selection methods help to optimize the process without reducing their performance on existing data.
- Federated learning: Core-set selection can be used to reduce the communication overhead in federated learning, where multiple devices collaboratively train a machine learning model without sharing all of their data.
- Medical imaging since with core set selection we reduce the amount of required sensitive data.
The amount of savings achieved through core-set selection in computer vision can vary depending on the specific task and dataset being used. However, studies have shown that core-set selection can significantly reduce the size of datasets without sacrificing performance. In some cases, core-set selection has been shown to reduce the dataset size by up to 90%.
Core-set selection algorithms can identify and remove redundant or irrelevant data points from the dataset, allowing the model to learn from a smaller set of data without losing important information. This reduces the dataset size, improves training speed, and enhances the generalizability of computer vision models.
In later posts we will dive in more details about active learning techniques and core-set selection strategies. In the meanwhile you can sign-up FiveBrane, the platform that shortens the way to build reliable AI solutions.